







Meta engineers have launched KernelAgent, a multi-agent system that automates the creation and tuning of GPU kernels for AI workloads. This open-source tool, available in the Meta-pyTorch/KernelAgent GitHub repository, uses large language models and a hardware-guided feedback loop to generate fast, verifiable Triton kernels from PyTorch programs.
Key Features
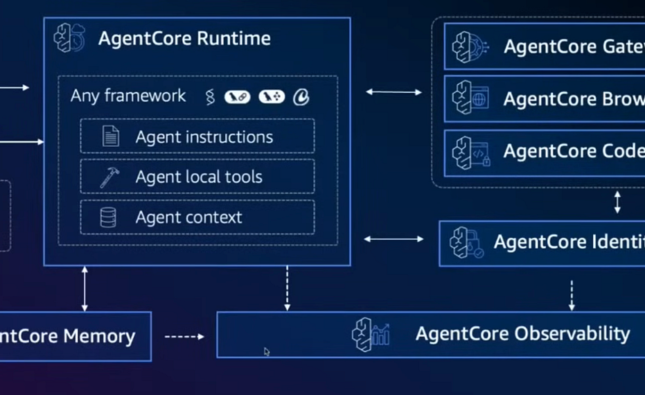
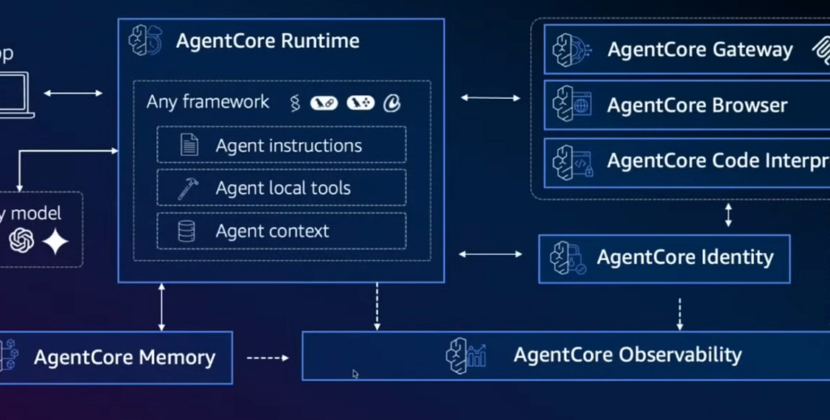
- Multi-agent system: KernelAgent splits the complex task of kernel optimization into dedicated roles. ProfilerAgent monitors and collects hardware performance data; JudgeAgent analyzes requests to identify areas for improvement; and the Optimization manager coordinates the workflow and decides which optimizations to pursue. These agents work together in cycles.
- Hardware-guided optimization: Instead of relying on static models like traditional compilers, KernelAgent bases its choices on real hardware performance data, including compute usage and memory bandwidth, gathered with NVIDIA Nsight Compute (NCU).
- Ongoing feedback loop: The system uses a closed-loop workflow.
- Profiling: The system collects hardware metrics when it runs the kernel for the first time
- Diagnosis: A powerful language model reviews the data to find performance bottlenecks.
- Optimization: another large language model creates an improved kernel based on these suggestions.
- Verification & Benchmarking: The system tests the new kernel to ensure it is accurate and performs well.
- Iteration: The process repeats, and agents learn from previous successes and failures saved in shared memory.
- The Optimization Manager explores several optimization paths in parallel, keeping only the best-performing kernels.
- KernelAgent identifies and fuses parts of PyTorch programs, replacing them with optimized Triton kernels.
Performance
On 100 L1 KernelBench tasks, KernelAgent achieved 2.02x speedup over previous kernels and averaged 1.56x faster than the default torch. compile, reaching 89% of hardware efficiency on an H100 GPU.
Optimizing GPU kernels is becoming more important for today’s AI workloads. As models get bigger and more specialized, performance increasingly depends on kernel efficiency rather than just the algorithms. However, manually tuning kernels requires significant expertise and an in-depth understanding of GPU hardware, memory, and performance trade-offs. The challenge only grows as more channels and kernels are added, and each new GPU architecture requires new optimization strategies.
In practice, skilled kernel engineers use a step-by-step approach to optimize kernels. They profile kernels with tools such as NVIDIA Nsight Compute and examine hardware performance counters to identify bottlenecks and make targeted improvements.
They ask questions like:
- Is the tiling strategy missing out on memory bandwidth?
- Does the kernel need a full redesign rather than just parameter tuning?
Often, they have to evaluate several kernel designs, each with its own bottleneck, before finding one that fully utilizes the hardware. This process works well, but it usually takes days or even weeks.
Modern compiler stacks have made big advances in automating kernel generation. For example, Torch.compile captures computation graphs and generates Triton kernels via graph transformations. Pattern matching and compiler rules, as well as other systems like TVM and XLA, employ similar tools to handle many common kernel patterns and deliver good performance from the start. Still, most compiler rules rely on static models rather than real measurements from running or actual hardware.
KernelAgent seeks to automate this diagnosis-driven optimization process by harnessing real hardware signals to steer Kernel’s tuning of forward-pass (inference) kernels, which directly impact latency and throughput. This system is built on three fundamental principles:
- For every hardware decision, both bottleneck identification and optimization selection should be based on precise profiling data.
- Adapt multiple optimization tactics concurrently. Given identical hardware data, there may be several viable optimization pathways. KernelAgent evaluates these alternatives in parallel, saving time and synthesizing previous strategies to generate superior algorithms.
- Iterate by learning from every round using shared memory. Optimization agents review what succeeded or failed, storing insights collectively to inform future cycles and avoid repeating errors.
Source: KernelAgent: Hardware-Guided GPU Kernel Optimization via Multi-Agent Orchestration