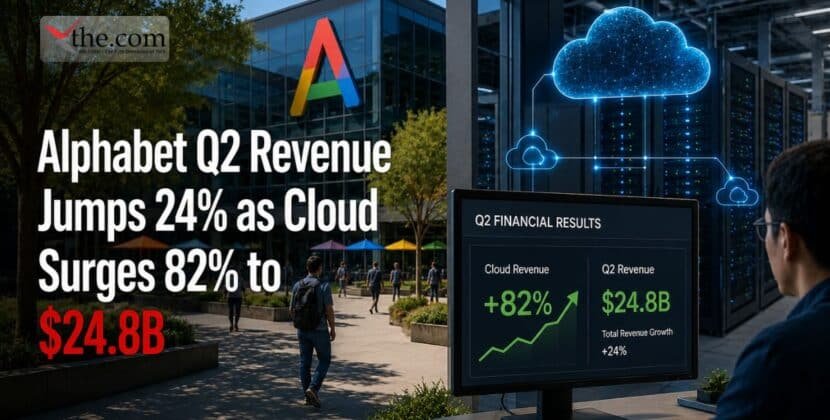








In April 2026, high-performance computing in the US is changing as the focus shifts from model training to large-scale agentic inference. The latest Nvidia AI chip roadmap update for US data centers highlights a move toward vertically integrated systems, where each data center rack serves as a single computing unit. Blackwell architecture is still the main choice for enterprise use, but the new Vera Rubin platform shows a strong move toward more advanced thinking machines. This roadmap helps US infrastructure providers plan for the power and cooling needs of the next generation of high-density racks exceeding 120 kW.
The Blackwell Ultra Era and the FP4 Performance
In January 2026, the B300 became the main chip for high-volume inference in major US cloud regions. It features 288 GB of HBM3E memory, enabling a single GPU to run a 70-billion-parameter model in FP16 without slowing down during quantization. The B300 is also the first chip to enable FP4’s widespread use in data centers, delivering 15 petaFLOPS of compute power. This efficiency helps US businesses lower their cost per token as they deploy autonomous agents in production.
Blackwell Ultra brings improvements not just in computing power, but also in networking. Thanks to the new ConnectX-8. By doubling internode bandwidth to 1.6T per optical module, Nvidia has removed the communication bottlenecks that affected earlier training clusters. Now, the US has hyperscalers that can connect thousands of GPUs with sub-microsecond latency, which is essential for reasoning models that need large KV caches. The Nvidia AI chip roadmap update for US data centers now stresses that networking speed is as important as chip performance.
Transitioning to the Vera Rubin Platform
In the second half of 2026, the roadmap introduces the Vera Rubin platform, now in full production following its early 2026 launch. Built on the TSMC N3 process, the Rubin GPU has 336 billion transistors and uses HBM4 memory for higher bandwidth. This platform is designed for agentic AI, in which models handle complex, multi-step tasks independently. By combining 36 Vera CPUs and 72 Rubin GPUs in a single NVL 72 rack, Nvidia aims to deliver 2.5 times the inference throughput of the Blackwell generation.
The Strategic Integration of the Groq Technology
One standout feature of the Vera Rubin architecture is its use of Groq’s new low-latency processors, enabled by a major licensing deal in late 2025. With this setup, the Rubin platform can send large-scale, real-time inference tasks to Groq’s LPU (language processing unit) while keeping its GPUs focused on heavy training and reasoning tasks. NVIDIA’s Dynamo software manages this mix, enabling US data centers to run different workloads in the same rack. This combination is a key part of Nvidia’s AI chip roadmap update for US data centers, helping meet the demand for instant response times in human-AI interactions.
Power Density and Liquid Cooling Mandates
The roadmap shows a significant increase in power needs, with B300 racks using about 1,400 W per GPU and Rubin-based platforms reaching rack densities of about 130 kW. For US data center operators, this means liquid cooling will be required, not just an optional upgrade starting in 2026. To help with this change, NVIDIA is working more closely with cooling infrastructure providers so that direct-to-chip cooling systems come built into the rack design. This change is needed to keep 300-billion-transistor chips stable under long, demanding workloads.
The roadmap also introduces the Rubin Ultra version expected in early 2027, which will increase memory capacity to 384 GB of HBM 4e. This upgrade lets US companies invest in the Vera Rubin ecosystem now, knowing their systems can handle even larger, multimodal workloads in the future by using NVLink6, which offers 3.6 TB of bandwidth per GPU. The Nvidia AI chip roadmap update for US data centers ensures the interconnect system stays up to date as new chips are released.
Long Term Outlook, The Feynman Generation
Looking ahead, Nvidia has begun discussing the Feynman architecture planned for 2028, which will include optical interconnects built into the silicon. This vision points to a future in which data centers no longer use copper cables, enabling the bandwidth needed for large-scale simulations. For now, US companies are working to secure Rubin GPUs, as production at TSMC remains very limited. Managing these supply chain delays has become a key skill for any organization involved in the AI infrastructure boom.
In summary, the current roadmap is a guide for the next stage of the US digital economy, where intelligence is seen as a high-performance utility. By moving from separate GPUs to fully integrated AI supercomputers, NVIDIA is giving US businesses the tools they need to build in and lead in autonomous systems. As the Blackwell Ultra is replaced by the Vera Rubin platform later this year, the main goal will be to balance computing power, energy efficiency, and fast networking. Following this roadmap is now a strategic must for staying competitive in the global AI race.
Source: Build a More Secure, Always-On Local AI Agent with OpenClaw and NVIDIA NemoClaw