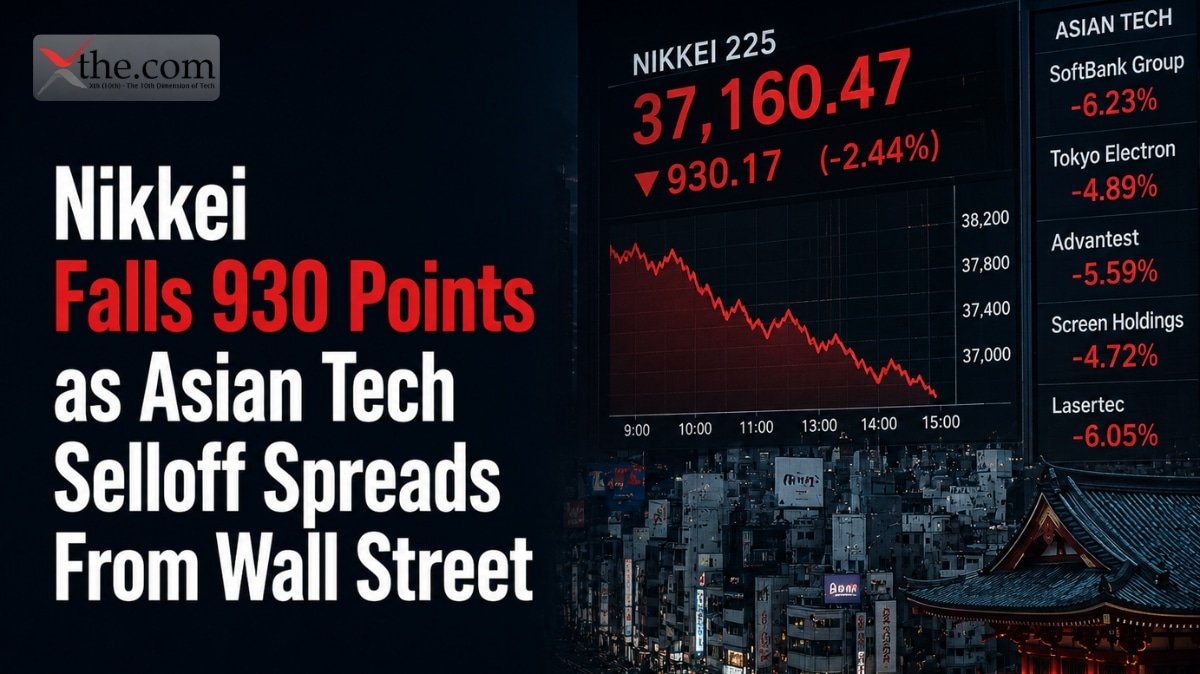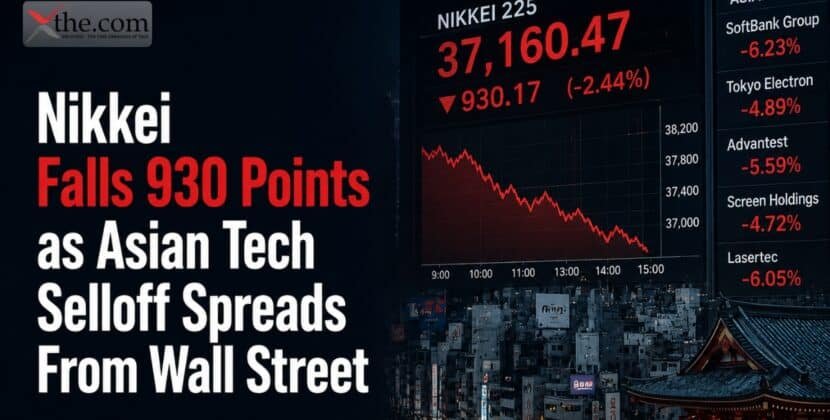









Recent API usage logs show that language models are using computational resources more efficiently. Developers have noticed that each request now uses fewer tokens while maintaining the same output quality. Since OpenAI API pricing is based on token usage, this change directly affects costs. These results suggest that optimization efforts for both models and applications are starting to pay off.
OpenAI Pricing and the Role of Token Efficiency
Cost and performance are closely linked when choosing an API. Because pricing depends on token usage, even small efficiency gains can save significant money. Recent logs show that it now takes fewer tokens to get the same or better results. This means token efficiency is improving in many situations.
For developers, this change affects how they design and scale applications. Using fewer tokens lowers costs but keeps performance steady. It also lets teams make more API calls without increasing the budget. This opens up more chances to try new ideas and add features.
What the Usage Logs Reveal.
Reduced Token Consumption per Request
The logs show that token use per interaction is steadily going down. This applies not just to simple questions, but also to complex multi-step prompts. The drop seems to come from better prompt handling and how the model structures its responses. Outputs are now shorter but still clear.
This improvement shows that models are matching input prompts and responses more closely. They now understand instructions better and avoid adding extra details. This directly helps save tokens.
Improved Output Structuring
Another reason for the improvement is how responses are formatted. Models now produce more organized outputs, reducing redundant information. For example, lists and summaries use fewer repeated phrases. This reduces the total token count.
Developers are also improving how they write prompts. Giving clearer instructions leads to more focused responses. This teamwork between users and models makes things more efficient. It shows that both sides play a role in the optimization.
Technical Drivers Behind the Efficiency Gains.
Model Level Optimization
Better model architecture is a big factor. New training methods and information-processing techniques help models work more efficiently. These changes mean models don’t need to give long answers and can be more accurate.
Better context management is another contributing factor. Models can retain and use relevant information. Improved context management also helps. Models can remember and use important information without repeating themselves. This lowers token use in longer conversations and makes responses more consistent. With clear and specific instructions, they reduce ambiguity. This leads to shorter, more precise outputs. It also minimizes the need for follow-up queries.
Prompt templates and reusable formats are now more common. These tools help make interactions more consistent and reliable across different applications. This boosts overall efficiency.
Impact on Application Development
Cost Optimization Strategies
Using fewer tokens directly impacts budgeting. Teams can use their resources more wisely, especially for large projects. The money saved can go toward new features or more usage.
Knowing how OpenAI API pricing works is even more important now. Developers need to watch how they use tokens and adjust their plans as needed. Designing for efficiency —efficiently can cut long-term costs, so optimization should be a main focus. Gains allow applications to scale more effectively. Increased usage does not necessarily lead to proportional cost growth. This is a key advantage for startups and growing platforms. It enables broader adoption of AI features.
Applications can now support more users or handle more complex tasks without needing a bigger budget. This flexibility encourages innovation and lowers the cost of getting started. Being efficient is now a real advantage.
Broader Implications for the Ecosystem
Standardization of Efficient Practices
As efficiency improves, new best practices emerge. Developers are sharing ways to use fewer tokens, like improving prompts and formatting outputs. Over time, these methods could become the norm. Meanwhile, this trend is pushing developers to be more disciplined in how they build AI. Efficiency is now expected, not just a bonus. It affects how tools are made and what users look for.
Competitive Pressure on Pricing Models
Improvements in better token efficiency could change how pricing works. Providers offer lower rates to match the drop in resource use. This could make prices more competitive and inspire new ways to bill for services. As efficiency improves, the value proposition changes. Users expect more output for the same cost. Providers must respond to these expectations.
Challenges and Considerations
Balancing Concise and Quality
Shorter responses help save money, but they still need to be high-quality. If you optimize too much, answers might become unclear or incomplete. Developers have to find the right balance, which takes testing and tweaking.
Efficiency shouldn’t make apps harder to use. Applications still need to meet users’ needs. Careful design ensures improvements really help and avoid unwanted side effects.
Monitoring And Measurement
Keeping track of token use is key to understanding how well things work. Developers need tools to watch usage as it happens. This information shows where to improve and helps make better decisions.
Regularly reviewing usage logs provides useful insights. It shows patterns and trends over time, which can guide efforts to optimize. This also helps keep things efficient as apps change.
Final Thoughts
The recent boost in efficiency is a big step forward for API-based AI systems. Using fewer tokens cuts costs and makes apps easier to scale and adapt. As things continue to improve, it’s important for developers and organizations to understand OpenAI API pricing. By optimizing both models and applications, teams can deliver the most value while maintaining strong performance.
Sources: Build on the OpenAI API Platform