








Amazon Web Services is upgrading its data center connections to 1.6T optical networking standards to address the growing communication tasks as thousands of processors sync data across distributed clusters. Doubling the bandwidth from 800G to 1.6T enables faster server connections and supports large-scale computing, computing models that require a rapid exchange rate. As demand increases, A-AWS is moving to 1.6T optical networks to ensure hardware doesn’t slow future digital device services.
The Physics Of High Velocity Data Transmission
Switching to 1.6 terabit-per-second (1.6T) speeds changes how light carries information through fiber-optic cables. AWS uses 200G-per-lane technology, which means each channel can transmit 200 gigabits per second, allowing eight high-speed channels (or lanes) to run over one optical interface. This setup makes the networking equipment simpler and increases each rack’s capacity. It also delivers a more efficient fabric, fabric architecture-a network structure that connects servers and devices, allowing fast, flexible data movement to manage the unpredictable traffic of modern data processing.
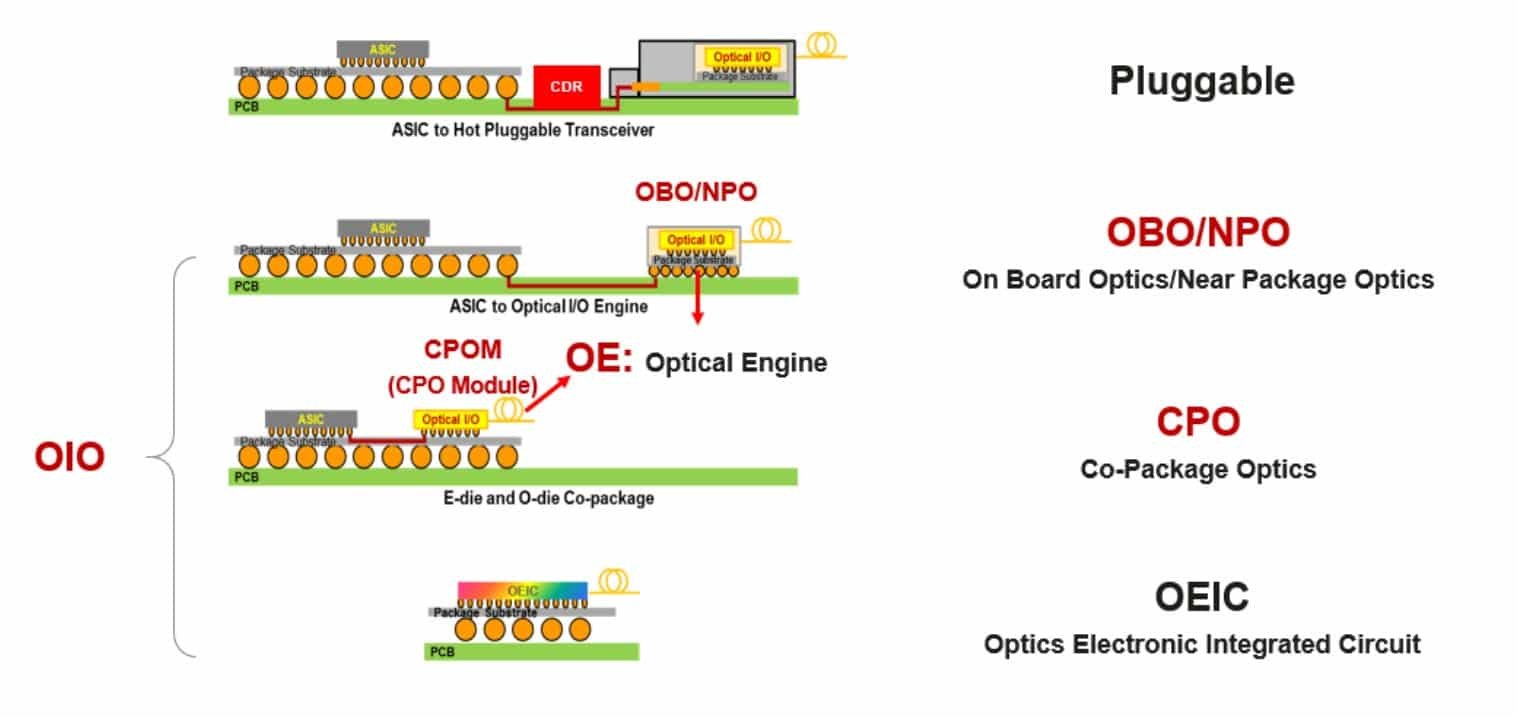
To manage the heat and power needs at these speeds, AWS is building co-packaged optics (CPO) directly into its custom networking switches. Traditional modules lose efficiency because electrical signals travel over copper before being converted to light. By placing the optical engine closer to the switch chip, AWS reduces signal degradation and lowers power consumption per gigabit. The photonic integration helps keep high-density data centers stable and enables the network to run at top speed without exceeding safety limits.
Resolving the Latency Crisis in Distributed Computing
A major challenge in contemporary computing is synchronous latency, in which processors must wait for data from other nodes before they can continue working. Even a few microseconds of delay in a cluster can result in thousands of idle cycles. The 1.6T standard uses ultra-low-latency protocols to deliver small, time-sensitive packets quickly. This supports the global state of a distributed task consistent across all our hardware.
AWS’s move to 1.6T optical networks also relies on forward error correction (FEC) algorithms that detect and correct data errors in real time during transmission in high-speed optical systems. This prevents the need to resend packets and ensures data accuracy and integrity at terabit speeds, where even minor interference can cause major problems. By strengthening the communications layer, AWS delivers predictable, consistent network performance for enterprise customers, enabling researchers to run complex simulations with full confidence in data integrity.
Scaling The Global Backbone For Uninterrupted Throughput
The 1.6T optics upgrade extends beyond single-server racks and includes inter-availability zone (inter-AZ) connections. These long fiber paths link different data center campuses within the same geographic region, providing redundancy and load balancing. Upgrading these backbones lets AWS move tasks between buildings based on power or cooling needs, enabling seamless workload migration and uninterrupted computing. This creates a fluid infrastructure, an adaptable system that quickly responds to changing needs.
AWS is also using next-generation optical amplifiers devices that simply amplify light signals to keep signals strong over long distances. These amplifiers increase the intensity of light pulses without adding the noise (unwanted interference) that often affects high-frequency waves. This enables high-fidelity connectivity, meaning reliable, clear data transfer across hundreds of miles of fiber, making a regional cluster work like one large computer. For users, this means speedier load times and more responsive apps, no matter where the hardware is. It moves the cloud closer to geographic transparency. The idea is that users do not notice where computing resources are physically located.
Addressing The Economic Facts Of Infrastructure Growth
Although moving to 1.6T requires a large capital investment the initial money spent on equipment it lowers operational expenditure (OPEX), the ongoing cost of running the system per terabit of data, by sending more data through fewer cables. AWS cuts the cost of cable management (handling and maintaining wiring) and port maintenance. The energy savings from 200G-per-lane signaling also help reduce the network’s total carbon footprint, which is the environmental impact of greenhouse gas emissions. This sustainability is important for global organizations that need to report their environmental effects.
The upgrade simplifies the hardware cycle by reducing upgrade frequency. By moving directly to 1.6T, AWS future-proofs its network for projected five-year data growth. This long-term technical deployment maintains the network’s competitive advantage. Partners and developers can now build more complex software with confidence that the network will scale to future needs. That stability supports technological risk-taking and drives industry innovation.
The Crystalline Pulse of the New Internet
As 1.6 terabit connections come online, the data center becomes more efficient and responsive. This shift lets us address delay as a technical challenge rather than a persistent issue. With time, bottlenecks can become rare, letting ideas move at the speed of light.
In the future, invisible systems will support our daily lives with care. As the world becomes more connected and responsive, technology will finally keep pace with human thought.
Source: AWS News Blog



















