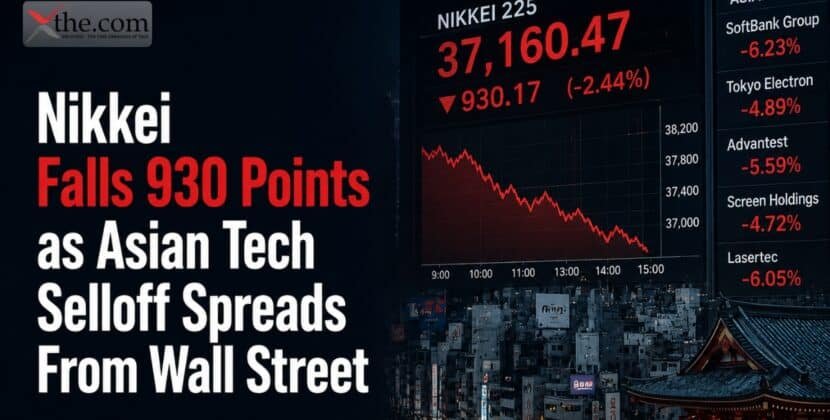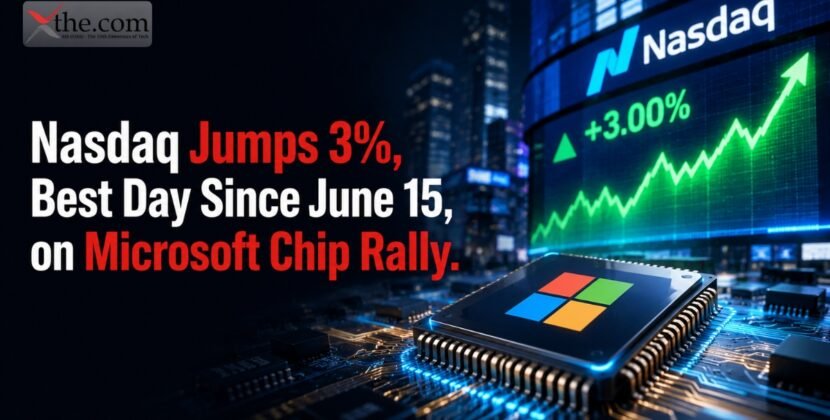










Cybersecurity incidents will no longer be managed confidentially behind closed doors. Starting in 2026, all U.S. Public Companies will be required to disclose information about material cyber incidents in a timely, structured manner.
The U.S. Securities and Exchange Commission has implemented new formal rules on cybersecurity disclosures that have changed how public companies report material cyber incidents, shifting them from a strategic decision to a required legal disclosure. The objective of the new rules is to provide investors with timely and accurate disclosures of potential risks that may adversely affect a company’s financial performance.
The implementation of these rules represents a seismic change for companies, linking cybersecurity directly to their financial reporting and governance.
Importance of SEC Cybersecurity Disclosure Rules
Before the rules were implemented, public companies had significant latitude in when and how they disclosed material cyber incidents. This generally resulted in public companies disclosing material cyber incidents on a delayed basis or having inconsistent reporting practices.
The intent of the new rule is to standardize public companies’ cybersecurity reporting process and thus require:
- Strict timelines for reporting material incidents.
- Increase the public company’s transparency to its shareholders.
- Hold the public company accountable at the executive level.
- Failure to comply with these rules can result in regulatory fines, legal exposure, and loss of confidence from their shareholders.
Key Requirements Under SEC Cyber Disclosure Rules
Mandatory Disclosure of Cybersecurity Incidents through Form 8-K Filing:
- Companies must disclose important cybersecurity incidents on Form 8-K filing.
- Companies are required to report any material cybersecurity incident within four (4) business days of the date the company determines the incident meets its materiality threshold.
- The report must include the nature and scope of the cybersecurity incident and the company’s assessment of its impact on the company.
- Companies should report the incident without undue delay, except if a delay is necessary for national security purposes.
This requirement allows general investors to have timely access to information about events that may affect a company’s performance.
Cybersecurity Risk Reporting on an Annual Basis:
Companies are also required to report additional information on their cybersecurity practices in their annual filings. Report on risk management strategies, procedures, and measures used to identify and reduce exposure to cybersecurity incidents; and historical loss information for events that have occurred from cybersecurity incidents.
The creation of this type of disclosure creates a continuous disclosure model rather than a reactive model.
Governance and Board Oversight
Cybersecurity is now a corporate board responsibility; therefore, the SEC has specified how a company’s leadership should be involved in overseeing cybersecurity risk.
- The Company Board is expected to be directly involved in cybersecurity strategy.
- The Company Board is expected to identify the executive(s) responsible for executing the company’s cyber risk strategy.
- The Company Board is expected to establish a formal reporting structure for cybersecurity incidents.
This process enables companies to incorporate cybersecurity into their overall corporate governance.
Cyber Incident Materiality
As companies grapple with what constitutes a “material” incident, one primary challenge is assessing how much loss the event would create in terms of finances, operations, reputation, laws and regulations, etc.
To determine materiality, businesses must establish an assessment process to evaluate these four factors as quickly as possible, so they can provide an accurate report in a timely manner.
Cyber Security Versus Transparency
There is a difference between providing total transparency as an SEC requirement versus being required to provide information that could be used to compromise your organization’s cybersecurity. It is up to the organization how they will communicate with their shareholders; however, organizations will use this balance of transparency vs security to:
- Provide communication that is sufficient to inform investors of the risks for the organization, and
- To provide detailed security risk mitigations to ensure their critical systems do not carry an additional level of risk.
In this manner, organizations are taking a “balanced” approach to their public disclosures in the current high-risk digital age.
SEC Cyber Disclosure Framework Overview
| Requirement | Timeline | Purpose | Impact |
| Incident Disclosure (Form 8-K) | 4 days | Investor awareness | High urgency |
| Annual Reporting | Yearly | Risk transparency | Long-term trust |
| Governance Disclosure | Ongoing | Accountability | Strategic alignment |
| Materiality Assessment | Immediate | Decision-making | Compliance accuracy |
Challenges Companies Are Facing
Despite straightforward suggestions, several companies fail to act on them. The primary concern is implementing internal procedures within the hard deadlines defined by the SEC.
Common sticking points include:
- Delays in identifying when there has been a cybersecurity event;
- Not having a coordinated response between IT, Legal, and Leadership teams;
- Inability to evaluate materiality quickly;
- Second-guessing because of reputational damage.
These points help highlight the need for a structured, well-practiced response strategy.
Conclusion
The SEC’s rules regarding cybersecurity disclosures are an example of how things are changing due to today’s digital economy, with companies being held accountable for managing cyber risks; investors want to know how companies manage their cyber exposure by illustrating cyber-risk controls in the normal course of doing business, continually, not just when an incident happens.
By embracing the SEC‘s rules early, organizations will establish compliance and build greater trust with stakeholders in a marketplace that continues to drive toward transparency, providing them with a competitive advantage.