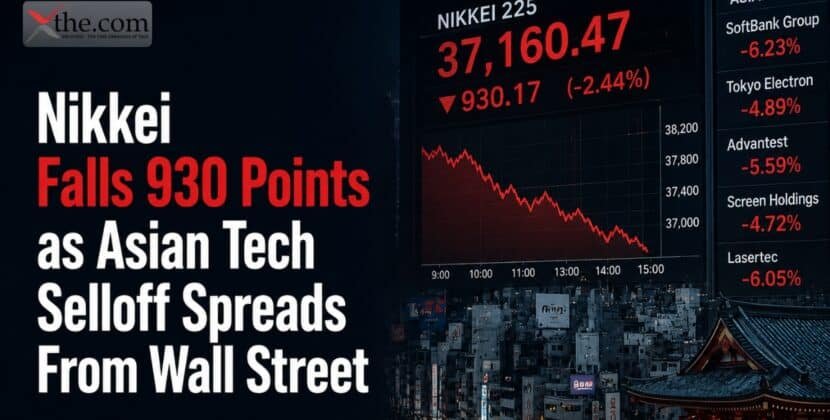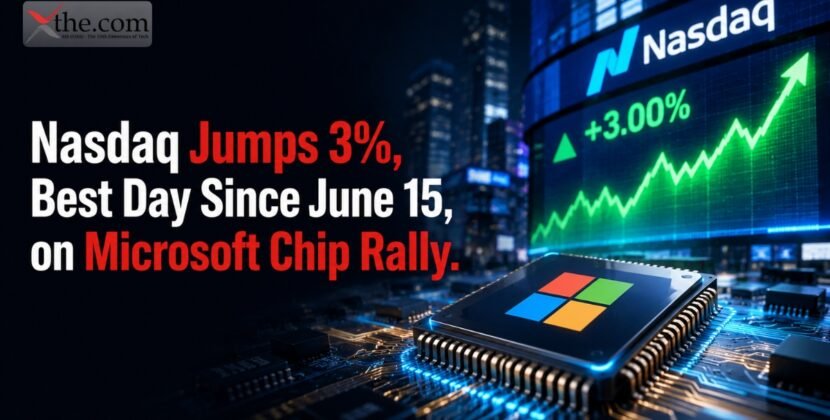










Apple has applied for a patent describing a display technology that can self-repair from various forms of damage, including small surface scratches. This technology uses new materials and innovative structural designs that enable a display to self-repair to its original shape without manual intervention, thereby likely increasing the device’s durability and lifespan.
According to the patent, the display will use specialized layers or coatings on the display surface that respond chemically or thermally to damage, allowing healing over time and, as a result, lessening visible wear and tear on the display and producing a device with an increased expected life.
Rethinking Device Durability
In recent years, new technologies have become very durable, but they will still receive wear and tear from daily use. Eventually, as scratches and micro-abrasions appear on phones, along with minor cracks, the phone’s appearance and functionality will be affected.
Apple’s Self-Repairable Display concept carves out a new path beyond simply using screen protectors/cases by creating a display with self-repairing features built right in. With the display working as part of the display hardware, the overall device will continue to look and work great for a long time.
There are many other companies developing hardware that is also built to last longer and perform better in general.
How Self-Healing Displays Work
According to the patent, ‘Dynamically Responding Advanced Materials,’ the material described may include advanced composites, such as polymers and layered composites, that can dynamically respond to damage by reorganizing their chemical structure after disruption.
Some examples of how materials can heal involve applying stimulation, such as heat, light, and/or electrical signals, to activate the material’s healing mechanism. For example, if an advanced material were subjected to a specific temperature range, it could close small scratches or smooth surface irregularities.
Apple intends to explore several means to ensure the healing process is effective and compatible with everyday device use.
Benefits for Everyday Users
The user experience will improve significantly because self-healing displays eliminate the need to repair or replace parts. The system will automatically fix minor damage that would normally require servicing, saving both time and costs.
The devices will maintain their visual appearance for extended periods, which is especially significant for premium products that depend on display excellence. This improves both resale value and product longevity.
Apple’s development demonstrates how advanced materials can create better user experiences while addressing environmental challenges.
Reducing Electronic Waste
The self-healing technology demonstrates broader benefits by reducing electronic waste. The rising amounts of discarded electronics result from damaged screens, which typically lead to device replacements.
The use of self-repairing displays in devices will enable longer operational lifespans, reducing the need for replacement. The initiative supports worldwide efforts to achieve sustainability while decreasing environmental effects.
Apple has increasingly emphasized sustainability in its product design, and self-healing materials will help the company achieve its sustainability objectives.
Integration with Existing Device Designs
The self-healing displays need to achieve commercial success because they must work with current device designs. The system requires touch sensor integration, connection to a protective glass layer, and proper functioning of internal components.
The technology needs to function seamlessly according to current device design requirements, which include slim designs and power consumption standards.
Apple’s patent shows the company plans to use these materials in upcoming products while maintaining its current design standards.
Competitive Landscape in Display Innovation
The race to improve display durability is highly competitive, with companies exploring various approaches such as stronger glass materials, coatings, and flexible designs.
Apple’s self-healing concept introduces a new dimension to this competition by focusing on active repair rather than passive resistance. This could differentiate future devices in a market where durability is a key selling point.
Self-healing technology will evolve into a core element that defines upcoming display technologies as innovation progresses.
From Patent to Product
The patented technology lacks commercial use because its actual implementation remains undetermined, which is common for most patents. The commercial use of patents occurs with established technologies or proven scientific advancements.
The research provides essential information about a company’s scientific priorities and its future development plans. Apple is currently investigating methods to enhance device durability through its research into self-healing materials.
The Future of Smart Materials
Self-healing displays belong to a broader class of smart materials that can change their properties in response to environmental conditions. The materials demonstrate potential uses beyond consumer electronics, including automotive, aerospace, and medical applications.
Smart materials research will lead to the development of devices that are both more durable and adaptable to user preferences.
Apple’s patent demonstrates how material science research will become increasingly vital for developing future technological advancements.
Conclusion: Toward More Resilient Devices
The patent for Apple’s self-healing display shows a future where devices can automatically repair themselves to limit damage from typical usage. The repair systems Apple developed for display materials create an innovative approach to building more durable, environmentally friendly products.
The technology will enable users to use their devices better, longer, and with less negative environmental impact.
Source: Google Patent