Cupertino, California | Dateline: Thursday, July 23, 2026
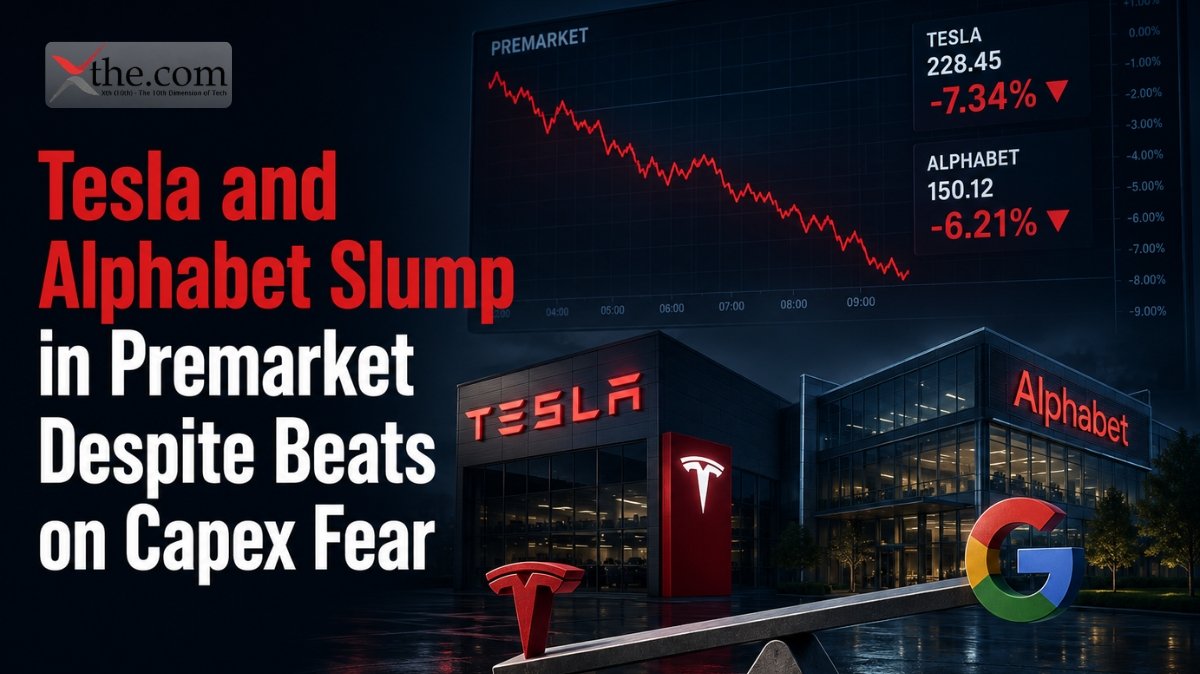
Investors saw a strong quarter on Thursday. However, the one thing Wall Street was hoping to hear—Apple—was missing.
Intel reported second-quarter revenue of $16.13 billion, up 25.4% from last year and marking its fastest growth in over fifteen years. Non-GAAP earnings were $0.42 per share, almost double the $0.22 analysts expected. Despite these strong results, the much-discussed Intel Apple foundry deal that helped drive the stock’s 178% rise this year remains just as it was in May: reported, unconfirmed, and still a major topic during the call.
The real story is the gap between Intel’s strong quarter and the unanswered questions concerning its customers. CEO Lip-Bu Tan talked about better yields, rising demand for AI servers, and more long-term supply deals. But he never mentioned Apple, and neither did anyone else from Intel’s leadership.
A Preliminary Deal Still Waiting for Confirmation
The Apple Intel manufacturing agreement first surfaced in a May 8 report from the Wall Street Journal, which cited people familiar with the matter describing more than a year of talks that had produced a preliminary arrangement. The Wall Street Journal Intel Apple report said Intel would manufacture select chips for Apple devices, with early attention centered on entry-level M-series parts destined for select iPad and Mac models. Both companies declined to comment at the time, and neither has said anything on the record since. Intel shares jumped roughly 14% the day the story broke; Apple added about 2%.
Thursday’s earnings call was billed as the moment that ambiguity might finally clear. It didn’t. Coverage of the results noted plainly that Intel did not reveal a major foundry customer, leaving investors and prospective partners still waiting for a name. In that sense, the Intel Apple foundry deal awaits confirmation just as much after this earnings season as it did before it, and the market is left parsing tone rather than transcript for indications about where things stand.
There was at least some news. Two days before the report, Intel announced Fortinet as the first external customer for its Intel 4 manufacturing process under Tan’s leadership. Fortinet’s next-generation Security Processor 6 will be made at Intel’s Fab 34 in Ireland. This is a real, named deal, but it is a smaller and less advanced win compared to what a partnership with Apple would mean.
Why an Apple Win Would Be Transformational
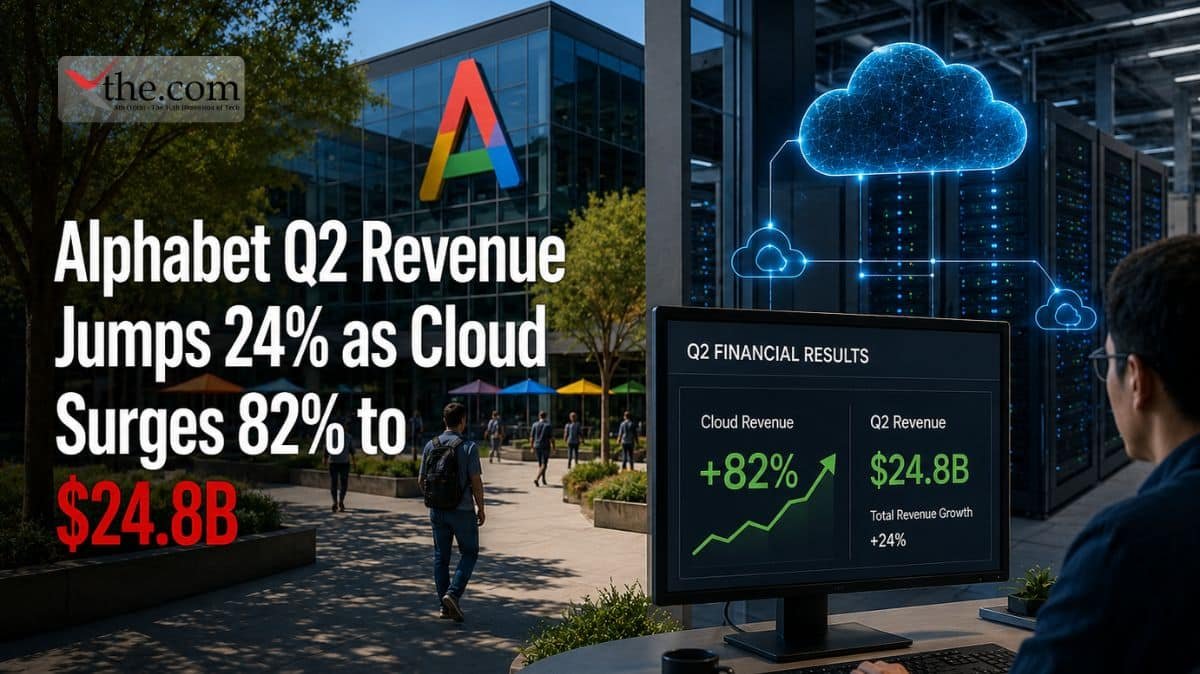
This context is important and explains why so many people focused on Apple during Thursday’s call. Intel Foundry brought in $5.76 billion in revenue for the quarter, up 31% from last year, but most of that still comes from making chips for itself, not for other companies. That difference is key to Intel’s turnaround story. A company that only makes its own chips is not a true foundry like Taiwan Semiconductor Manufacturing Co.; it is just a manufacturer with extra capacity. Intel foundry customer confirmation from a marquee name changes that calculus entirely.
Apple would be the most credible validation available. The company is famously exacting about supply chain quality, and it has relied almost exclusively on TSMC for both its A-series and M-series silicon since severing ties with Intel’s CPUs in 2020. If Apple trusts Intel’s Oregon fabs with even a modest slice of its silicon volume, that decision tells every other prospective customer — Nvidia, Qualcomm, AMD, and the hyperscalers alike — that Intel’s advanced manufacturing has cleared a bar Apple would not lower for anyone. Analysts have argued Intel has already worked through its roughest patch and earned status as a credible second source; a confirmed Apple relationship would turn that argument from a plausible thesis into a fact.
The 18A Question
Much of the speculation centers on Intel 18A Apple customer scenarios, since 18A is Intel’s most advanced node currently in production and the one most comparable to TSMC’s leading-edge offerings. Reporting has suggested Apple’s initial interest involves 18A variants for lower-end M-series chips, with the more advanced 14A node — not expected to reach volume production until 2029 — potentially entering the conversation for iPhone processors further down the road. Intel’s own commentary this quarter pointed to continued yield gains across its process lineup, along with new long-term agreements, including one with Google, for server CPUs and custom silicon. None of that commentary named Apple specifically, and that omission was audible.
What the Silence Signals About Intel’s Pivot
The wider story here is Intel’s Intel contract manufacturing pivot, the years-long effort to transform a company that once existed solely to design and sell its own chips into one that additionally builds chips to order for anyone willing to pay. That shift carries real financial difficulty — Intel posted a GAAP net loss of $2.16 per share this quarter, mainly because of a $12.53 billion non-cash charge related to the CHIPS Act escrow. Building trust with outside customers is also a challenge, and it took TSMC many years to do the same. Each quarter without a big-name customer makes it a bit harder for Intel to prove itself, even as its product numbers get better. Data Center and AI revenue rose 59% to $6.26 billion, and Client Computing grew 13% to $8.88 billion. Intel expects Q3 revenue between $15.8 billion and $16.8 billion. These are strong results, but they do not answer whether Apple will sign on.
That is precisely why the Intel contract manufacturing pivot credibility question won’t be settled by a single earnings report. Tan has said he does not name customers until they are ready, a policy he has repeated in past interviews. CFO Dave Zinsner has said that the second half of 2026 and early 2027 is when foundry deals should become, as he put it, more concrete. Fortinet was the first customer in that timeframe. Whether Apple will be the next is still unknown, and Thursday’s call did not provide an answer.
Intel’s stock already shows a lot of optimism, trading at a higher value because investors expect the foundry business to grow significantly in the next few years. This optimism will keep putting pressure on the company to provide updates. Until Intel or Apple officially announces details about the deal first reported by the Journal in May, the market will keep looking to each earnings call to verify that it still has not come.
Source: Intel results to test if AI-fueled rally has room to run