








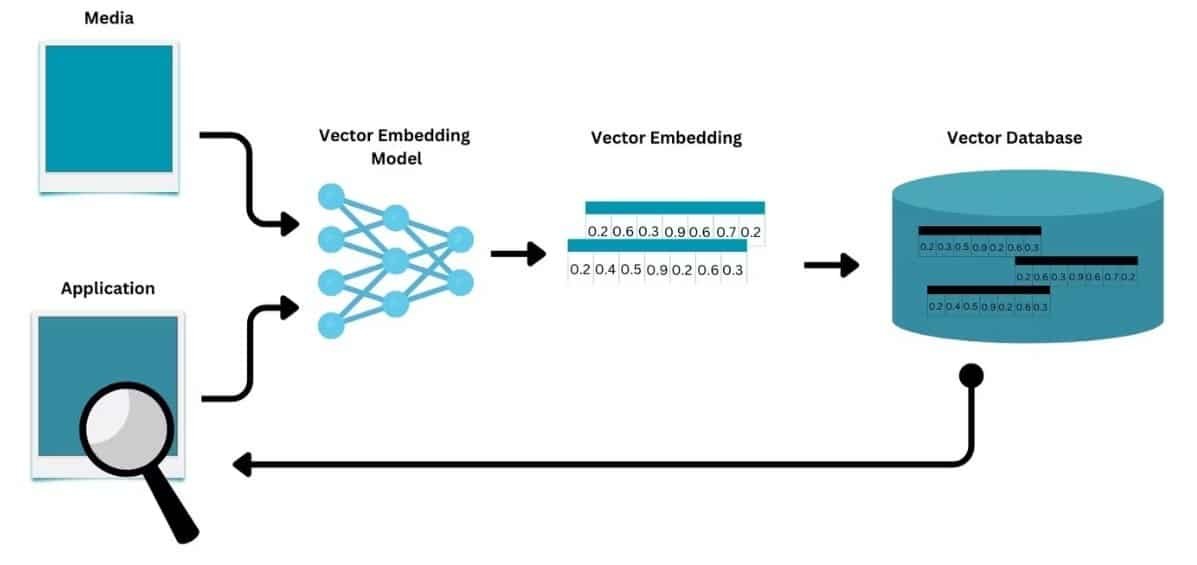
Continuous AI pipelines are ready for real-world use as more companies move to streaming data instead of relying on static databases. Systems now focus on dynamic data ingestion and processing. Vector database AI is key to this change, enabling quick indexing and retrieval of complex data. As a result, organizations are rethinking how they build, update, and scale smart applications.
Why Vector Database AI Powers Continuous Pipelines
Traditional AI systems use batch processing, collecting and handling data in set cycles. This method causes delays between when data is created and when it can be used. As businesses need quicker responses, batch workflows are becoming less useful.
Vector databases solve this problem by allowing updates in small steps. New data can be added and indexed without stopping current operations. This is important for maintaining system accuracy when inputs change frequently.
Real-time pipelines work well with this setup. They keep data moving nonstop from its source to the model and back to decision systems. This creates a smooth cycle of data intake, processing, and action.
From Static Models To Continuous Learning Systems
In the past, AI models were seen as fixed tools that needed to be retrained periodically. Updates happened on a schedule, which often meant predictions became outdated between cycles. This led to performance gaps, especially when things changed quickly.
In vector-based systems, models can be adjusted more often. New data is added to the database and can be used right away. This lets systems react to new trends without waiting for a full retraining.
Real-time pipelines keep this process running smoothly. Data moves nonstop, so systems can learn and adjust as things happen. This makes AI more responsive and accurate.
Operational Impact Across Enterprise Use Cases
Companies use continuous pipelines where timing matters most. For example, in e-commerce, recommendation engines update in real time based on user behavior. This means customers get better suggestions and companies see higher conversion rates.
In cybersecurity, systems watch data streams to spot problems as they happen. Finding issues right away means faster responses and less damage. These examples show why continuous data processing is valuable.
Customer support platforms also gain from this method. AI can update knowledge bases in real time, making answers more accurate. This improves the user experience and reduces the need for manual updates.
Integration Challenges And System Design
Despite these benefits, setting up continuous pipelines takes careful planning. Companies need to ensure that data ingestion, storage, and retrieval work closely together. If anything is out of sync, the whole process can break down.
Scalability is also important. As data grows, systems need to handle more work without slowing down. This means using smart indexing and managing resources well.
Data quality matters even more in continuous systems. If errors are not caught early, they can spread fast. Companies need strong checks to keep their systems reliable.
Strategic Role of Data Infrastructure
Moving to continuous pipelines puts new pressure on data infrastructure. Systems need to ingest data quickly and retrieve it with minimum delay. This calls for advanced storage and processing tools as a foundation for this infrastructure. It enables efficient handling of complex data types, such as text, images, and embeddings. This capability is essential for modern AI applications.
Companies are also investing in tools that monitor and improve pipeline performance. These tools show how data moves and how systems behave. Results keep things reliable and efficient.
Risk and Opportunity in Continuous AI Adoption
The transition to continuous pipelines offers significant opportunities. Organizations can achieve faster insights and more accurate predictions. This leads to improved decision-making and competitive advantage.
However, there are also real risks. Systems that still use old batch methods may fall behind. As more competitors adopt continuous models, the performance gap widens.
Batch AI is becoming outdated in this new environment. Companies that do not adapt may see higher costs and lower efficiency. This shows why it is urgent to modernize.
Future Direction of AI Pipelines
AI pipelines are moving forward/ AI pipelines are moving toward more automation and integration. In the future, systems will likely mix nonstop data intake with advanced analytics and decision-making. This will cut down on manual work even more.
Better infrastructure will help make this shift possible. New hardware and software will allow for faster processing and easier scaling. This means more organizations can use continuous pipelines.
Developers will be important in building these systems. They need to design setups that balance speed, reliability, and flexibility. This takes a strong grasp of both data and AI technology.
Closing Perspective On Continuous AI Systems
Aligning Data Flow With Business Needs.
Organizations are matching their data strategies to the needs of continuous processing. Systems need to give insights as things happen, not after a wait. This makes them more responsive and efficient.
Balancing Speed And Control
Continuous pipelines need cache management to stay accurate and reliable. Companies must put controls in place to stop errors from spreading. Keeping this balance is key to building trust in AI systems.
Building Long-Term Competitive Advantage
Companies that use continuous AI pipelines will have a long-term advantage. They will work faster and more accurately than others. Vector database AI will remain a key part of this change.
Source: MongoDB Blog












