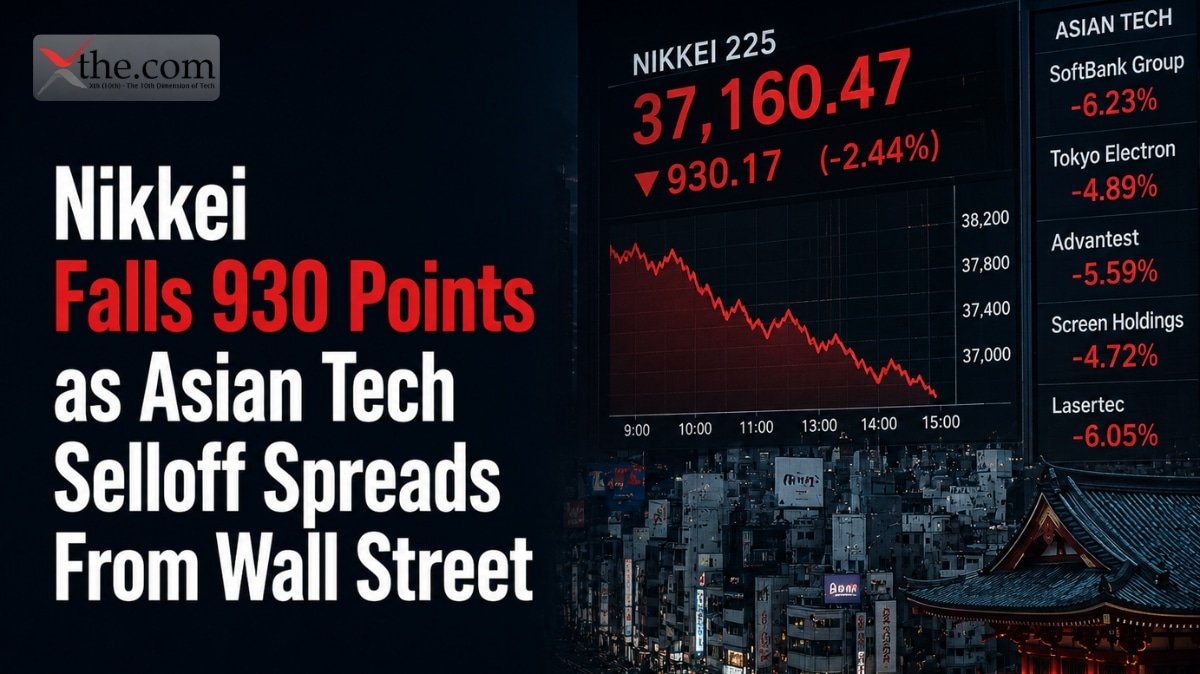









Firmware logs emerging from NVIDIA’s Arizona fabrication environment reveal a system quietly rewriting how large-scale compute believes, behaves under stress. Engineers observed GPU nodes failing, rerouting, and reintegrating without human intervention. This development sits at the center of AI infrastructure in the USA, self-healing clusters, and GPU automation, where uptime is no longer tied to manual oversight. The implications extend beyond performance into governance and trust.
Inside NVIDIA’s Experimental Cluster Design
NVIDIA’s test environment is different from a standard lab. It closely matches real NVIDIA data centers where thousands of GPUs work together in tightly managed clusters. These clusters run distributed workloads that need constant coordination.
The Arizona facility serves as a controlled testing ground. Engineers intentionally introduce failures to see how the system reacts. Rather than sending alerts, the system automatically fixes these problems.
This change moves away from traditional fault management. In the past, engineers checked every recovery step. Now, the firmware and orchestration layers make these decisions automatically.
How Self-Heal Mechanisms Operate
Failure detection and autonomous rerouting in AI infrastructure, USA. Self-healing clusters, GPU automation.
The system’s main feature is fast failure detection. GPUs continuously send telemetry signals, which are continuously checked. If something unusual happens, the system isolates the affected nodes in milliseconds.
The system then moves workloads to healthy nodes. This is similar to rerouting traffic in a network, but on a much larger scale. It helps prevent a single failure from causing larger outages.
These actions are governed by embedded AI recovery systems. They rely on historical patterns and predictive modeling. The system doesn’t just react; it anticipates instability.
Role of Cluster Orchestration Layers
The orchestration layer serves as the system’s decision maker. It manages resources, moves tasks, and keeps the system balanced. This is why cluster orchestration is so important.
Unlike fixed schedulers, this system adapts in real time. It changes how computing power is distributed based on current needs. This flexibility helps clusters keep performing well even under pressure.
This orchestration works closely with hardware signals. It connects the hardware and software layers. The result is a single control node that makes decisions quickly.
Operational Gains and Efficiency Metrics
Initial results from the Arizona tests show clear improvements. Downtime is shorter and happens less often. Sometimes failures are fixed so quickly that outside monitoring tools do not even notice them.
This directly affects NVIDIA data centers. Less downtime means higher usage rates and less work for engineering teams.
Efficiency improvements also reduce energy use. By spreading out workloads, the system avoids overloading certain nodes. This results in more balanced power use across the cluster.
The Trade-Off: Visibility Versus Autonomy
Reduced human oversight in AI infrastructure usage, self-healing clusters, and GPU automation.
While autonomy makes systems more resilient, it also brings new challenges. Engineers can no longer see every step in the recovery process, which makes it harder to audit what happened.
In traditional systems, every failure and fix is recorded for review. In this new setup, many actions happen out of sight. The system often solves problems before any alerts are sent.
This creates gaps in monitoring. It becomes harder to find the root cause of problems later. For industries with strict rules, this lack of transparency could be a serious issue.
Risks in AI-Driven Recovery Decisions
The reliance on AI recovery systems also introduces uncertainty. These systems make decisions based on learned patterns. While effective, they are not always explainable.
Unexpected interactions between nodes can cause problems that are hard to predict. Without human checks, these issues might last longer. This is especially worrying in critical environments.
The main challenge is balancing speed and accountability. Quick recovery is important, but not if it means losing track of what happened. Each organization must decide how much control to keep.
Implications for Future Data Center Architecture
The Arizona experiment points to a bigger change in the future. NVIDIA data centers may focus more on autonomy than manual control. This could change how infrastructure is built and managed.
Architectural data center designs will likely become more modular. Each part will need to work on its own, but still fit together smoothly. This aligns with the principles of large-scale cluster orchestration. Dors may also embed more intelligence directly into hardware. Stronger level decision-making reduces reliance on external systems. It brings resilience closer to the source of computation.
Industry Response and Competitive Pressure
Other companies in AI infrastructure are paying close attention. Autonomous recovery systems could set businesses apart. Those who use similar models may see better uptime and efficiency.
However, whether these systems are adopted will depend on trust. Companies need to know how the systems act predictably. That’s why transparency and validation will be important.
The conversation is shifting from capability to control. It’s no longer just about what systems can do, but how they do it. That distinction will shape future deployments.
Balancing Autonomy And Accountability In AI Infrastructure USA Self-Healing Clusters GPU Automation
The rise of self-healing clusters brings both benefits and challenges. Systems get stronger and more efficient, but the stacks that make them resilient become harder to see.
Organizations need to rethink how they monitor these systems. Old tools might miss important details. New methods will be needed to see what’s happening without slowing down recovery.
In the end, trust will decide if this model succeeds. Engineers need to feel confident in systems they can’t fully monitor. That confidence will shape how widely these technologies are used.
Conclusion: Redefining Control in Autonomous Compute Systems
NVIDIA’s Arizona tests show a major change in infrastructure design. Systems are starting to manage themselves, so they need less human help. This increases efficiency but also challenges old ideas about oversight.
Bringing together cluster orchestration and smart recovery systems marks a new way of running data centers. The focus is now on keeping things running smoothly, not just on control. Still, this approach needs new ways to ensure accountability.
As more companies use these systems, the industry will have to balance autonomy and oversight. The future of AI infrastructure will depend not only on how resilient systems are, but also on how openly that resilience is managed.
Source: Build a More Secure, Always-On Local AI Agent with OpenClaw and NVIDIA NemoClaw